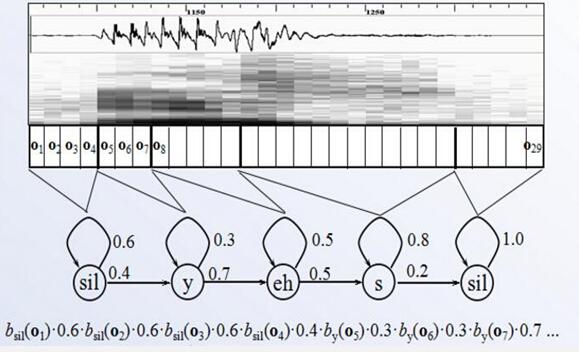
下面简明讲述GMM-HMM在语音识别上的原理,建模和测试过程。为了便于读者理解,以一个词的识别全过程作为例子。
1、将声波分割成等长的语音帧,对每个语音帧提取特征(例如,梅尔频率倒谱系数)
2、对每个语音帧的特征进行GMM训练,得到每个语音帧frame(o_i)属于每个状态的概率
3、根据每个单词的HMM状态转移概率计算每个状态序列生成该语音帧的概率。 哪个词的HMM序列计算出来的概率最大,就判断这段语音属于该词)





用户访问量
注册用户数
在线视频观看人次
在线实验人次
下面简明讲述GMM-HMM在语音识别上的原理,建模和测试过程。为了便于读者理解,以一个词的识别全过程作为例子。
1、将声波分割成等长的语音帧,对每个语音帧提取特征(例如,梅尔频率倒谱系数)
2、对每个语音帧的特征进行GMM训练,得到每个语音帧frame(o_i)属于每个状态的概率
3、根据每个单词的HMM状态转移概率计算每个状态序列生成该语音帧的概率。 哪个词的HMM序列计算出来的概率最大,就判断这段语音属于该词)
¥ 5999
·难
·36
¥ 9999
·难
·10
¥ 7999
·难
·13
¥ 199
·易
·36
¥ 899
·适中
·16
¥ 1688
·适中
·206
¥ 28000
·难
·170
¥ 199
·偏易
·3592
¥ 100000
·难
·175
¥ 998
·难
·14
¥ 1899
·难
·17
¥ 199
·易
·343
¥ 5999
·适中
·37
¥ 6999
·难
·21
¥ 5999
·难
·18
¥ 3999
·难
·19
¥ 2999
·难
·64



 周一至周五 9:00-17:30
周一至周五 9:00-17:30
 南京市秦淮区光华路街道
南京市秦淮区光华路街道
中国云计算创新基地A座

服务热线:400-885-5360
高校合作:025-83708922
微信客服: 15366173274

云创智学抖音号

云创智学微信公众号
 备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
备案:苏ICP备11060547号-1 许可证编号:苏B2-20200268
©2011-2021 Cstor.cn 版权所有.南京云创大数据科技股份有限公司(股票代码:835305)


















